使用flashback query巧妙抽取指定数据
本文共 1998 字,大约阅读时间需要 6 分钟。
在生产环境中存在着大量的数据,和业务是密切相关的。比如系统中的某个业务流程出现了问题,如果想复现就会显得非常困难,甚至是不太可能的,比如电信系统中存在着大量的客户信息,相关联的表的数据量都基本在千万,亿级。 如果要抽取,是全量抽取还是增量抽取。全量抽取可行,但是实际操作起来也不现实,如果要在测试环境中复现,可能需要大量的存储空间,而且相比来说也显得有些浪费,同事对于数据安全也是很大的隐患,毕竟我们不愿意客户信息这么轻易的暴露出来。 如果增量的,问题的关键是怎么增量,比如从100万客户信息中抽取一个客户的信息,按照这个要求抽取某个表的数据还是可行,但是如果很多表之间存在依赖,存在关联,很多表抽取就会是一个很大的困扰,毕竟对于dba来说,要控制这个抽取过程而且还要兼顾业务,是很困难的。 除此之外,还有一个主要问题就是在大批量数据中,怎么保证数据的事务一致性,比如存在表customer,subscriber,一个客户customer下可以对应多个用户subscriber,如果我们定位customer下的某个subscriber,这个时候,可能会有很多的事务在运行,我们需要同时保证subscriber相关的表的数据在同一个事务内是一致的。这对于抽取数据复现来说就是最基本的数据保证了。所以从抽取难度上和数据完整性上我们需要做一些工作。 其实我们可以巧妙的利用flashback query来完成这个看似不可能完成的任务。 我画了如下的图标进行解释。 首先在数据源头的schema中存在着一些表,我们假设为table1,table2,table3... table1,table2,....这些表之间是存在着一些对应关系的。比如customer表的customer_id和subscriber表中的customer_id是对应的。subcriber表的subscriber_id和产品订购表是存在关联的,这些关联关系至关重要。 即图中绿色的部分,这些都是一些表关系的定义,根据表中的字段进行映射。这样一个几百万数据的表根据映射关系可能就会过滤出来很少的数据来。 这个抽取的过程怎么保证事务数据的完整性呢,这个时候就需要flashback query来完成。在抽取的时候我们会根据需要的时间戳来作为数据抽取的基准时间,所有的关联的表都会基于这个时间戳进行抽取。 比如对于customer表,我们提供了customer_id=100 抽取customer表就会是下面的样子。 select * from customer as of timestamp xxxxx where customer_id=100; 如果customer和subscriber的映射关系是customer_id 则抽取subscriber就是 select *from subscriber as of timestamp xxxxx where customer_id=100; 以此类推,中间的蓝色柱子就代表抽取的基线时间。 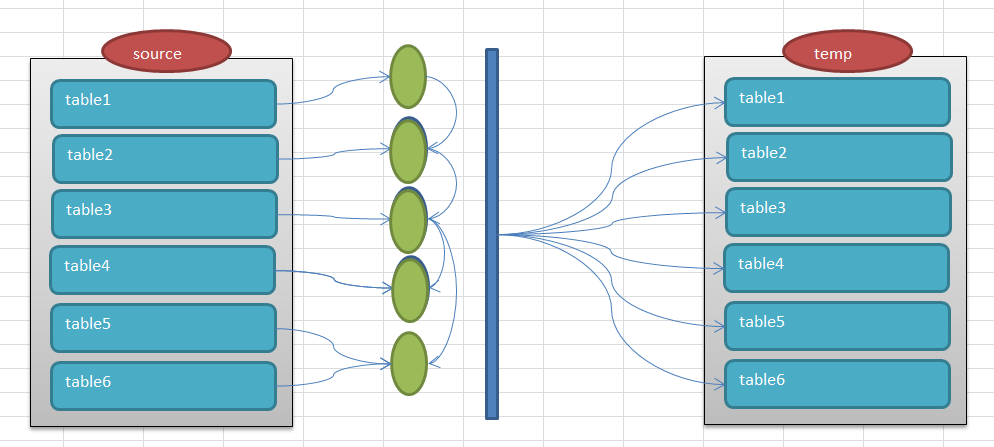 如果抽取的进展顺利,这些数据是能够很快抽取抽起来的,那么问题来了,怎么生成dump文件呢,这个时候我们可以考虑使用一个临时的schema来存在这些抽取的表数据,因为抽取的数据量是很小的,所以可以考虑使用一个临时的schema,直接在这个schema中导出数据即可。 即图中右半边的temp schema。 有了临时的schema,那么抽取的数据是怎么放到临时的schema中呢,还是使用最普通的ctas 对于customer表使用 create table customer nologging as select * from customer as of timestamp xxxxx where customer_id=100; 对于subscriber表使用 create table subscriber nologging as select *from subscriber as of timestamp xxxxx where customer_id=100; 因为这个schema的临时使用,实在找不出需要更多日志的理由,所以可以考虑直接使用logging选项来,加快临时表的生成速度。这样数据就会顺利在temp schema中生成,这个时候就跟钢铁导入磨具已经成型了,后期的加工就更加灵活了。 在哪个测试环境需要我们就可以灵活的使用exp/expdp来导出dump,根据需要导入制定的环境了。 整个过程还是比较简单的,但是其中还是有很多的细节需要注意,一个是抽取的逻辑,这个需要和开发,业务部门进行配合,把表的依赖,关联关系确认,另外就是抽取的粒度,尽量保证抽取的粒度要小,即最好提供限定的个别id来,如果抽取的数据量大了,对于系统的负载来说也是很高,得不偿失。
如果抽取的进展顺利,这些数据是能够很快抽取抽起来的,那么问题来了,怎么生成dump文件呢,这个时候我们可以考虑使用一个临时的schema来存在这些抽取的表数据,因为抽取的数据量是很小的,所以可以考虑使用一个临时的schema,直接在这个schema中导出数据即可。 即图中右半边的temp schema。 有了临时的schema,那么抽取的数据是怎么放到临时的schema中呢,还是使用最普通的ctas 对于customer表使用 create table customer nologging as select * from customer as of timestamp xxxxx where customer_id=100; 对于subscriber表使用 create table subscriber nologging as select *from subscriber as of timestamp xxxxx where customer_id=100; 因为这个schema的临时使用,实在找不出需要更多日志的理由,所以可以考虑直接使用logging选项来,加快临时表的生成速度。这样数据就会顺利在temp schema中生成,这个时候就跟钢铁导入磨具已经成型了,后期的加工就更加灵活了。 在哪个测试环境需要我们就可以灵活的使用exp/expdp来导出dump,根据需要导入制定的环境了。 整个过程还是比较简单的,但是其中还是有很多的细节需要注意,一个是抽取的逻辑,这个需要和开发,业务部门进行配合,把表的依赖,关联关系确认,另外就是抽取的粒度,尽量保证抽取的粒度要小,即最好提供限定的个别id来,如果抽取的数据量大了,对于系统的负载来说也是很高,得不偿失。
如果抽取的进展顺利,这些数据是能够很快抽取抽起来的,那么问题来了,怎么生成dump文件呢,这个时候我们可以考虑使用一个临时的schema来存在这些抽取的表数据,因为抽取的数据量是很小的,所以可以考虑使用一个临时的schema,直接在这个schema中导出数据即可。 即图中右半边的temp schema。 有了临时的schema,那么抽取的数据是怎么放到临时的schema中呢,还是使用最普通的ctas 对于customer表使用 create table customer nologging as select * from customer as of timestamp xxxxx where customer_id=100; 对于subscriber表使用 create table subscriber nologging as select *from subscriber as of timestamp xxxxx where customer_id=100; 因为这个schema的临时使用,实在找不出需要更多日志的理由,所以可以考虑直接使用logging选项来,加快临时表的生成速度。这样数据就会顺利在temp schema中生成,这个时候就跟钢铁导入磨具已经成型了,后期的加工就更加灵活了。 在哪个测试环境需要我们就可以灵活的使用exp/expdp来导出dump,根据需要导入制定的环境了。 整个过程还是比较简单的,但是其中还是有很多的细节需要注意,一个是抽取的逻辑,这个需要和开发,业务部门进行配合,把表的依赖,关联关系确认,另外就是抽取的粒度,尽量保证抽取的粒度要小,即最好提供限定的个别id来,如果抽取的数据量大了,对于系统的负载来说也是很高,得不偿失。 转载地址:http://fjthl.baihongyu.com/
你可能感兴趣的文章
C语言 模拟三次密码输入
查看>>
NagiosQL插件的安装应用
查看>>
MVC设计模式的总结
查看>>
muddleftpd配置和用法
查看>>
Oracle 学习之RMAN(九)BACKUP常用参数
查看>>
如何对待上司的弱项(或缺点)
查看>>
【C#入门经典(第五版)】第二章 编写C#程序
查看>>
Cassandra – 数据结构设计概念和原则
查看>>
编译安装python3.7和ipython
查看>>
SSDCRM正式推出基于linux系统的一键安装版
查看>>
js prototype 。 网上摘抄
查看>>
Fastdfs安装心得
查看>>
sql入门
查看>>
统一设置Eclipse编码
查看>>
zabbix 修改默认的/zabbix 斜杠
查看>>
Centos vmware克隆系统后无法启动网卡
查看>>
Linux下日志(Log)服务器/客户端配置实验
查看>>
python高效计算2的次方(位左移)和整数与2的次方的乘积
查看>>
正则表达式语法
查看>>
Cisco交换机密码破解方法
查看>>